Simulation and Virtual Reality
“Productivity is never an accident. It is always the result of a commitment to excellence, intelligent planning, and focused effort“ (Paul J. Meyer)
SIGEDA Product: Synthetic Images Generator for Data Augmentation from VR Environments for Deep Learning and Computer Vision projects
ITCL has been developing several tools to generate synthetic datasets that allows rendering thousands or millions of labelled images to train Deep Learning Computer Vision algorithms.
The related family of products named SIGEDA “Synthetic Images Generator for Data Augmentation” whose core can be used or personalized to tackle different problems. ITCL has done some specific implementations (shown below) to generate labelled data for Ergonomic Pose Estimation and Object Localization and Clasification. The core of the current system allows us to easily create new personalized solutions.
Hereinafter a generic overview of what is currently integrated into the core:
- Multiple backgrounds available by means of seleting several 3D environments.
- Selection of several pre-defined cameras positions and angles.
- Possibility to add a fully controllable camera to navigate inside the environment getting specific angles or positions if needed.
- Camera parameter configuble such as: FOV, resolution, intrinsic parameters (focal length, etc), and optics aberrations.
- Detection of occlusions between elements.
- Labels related to the elements of interest: 3D position, 2D position in the image and Regions of interest.
- Generation of images for dense segmentation problems.
- Other specific tools of behaviour needed for the specific problem (e.g: Animation of the 3D Avatar, random states in 3D objects, animations, sequences, multicamera per frame…)
More information
Objectives
- The main objective is to have an efficient way to generate of big amount of synthetic data. Our current solution can generate around 400-1.000 labelled images per minute in a commercial PC (i7 + Nvidia Geforce 2060RTX laptop) depending on the resolution and application. The solution can be easily scaled.
- Generation of enough variability in the images, environment, point of view, avatars… that avoid overfitting during the training stage of the neural networks.
- High versatility in the labelled information. As we are in a virtual environment all the elements are perfectly known and can be used as a Ground truth. It is possible to get any info related to the position, state, orientation, colour, characteristics… of any object in the environme
We will show hereinafter what we have already implemented, nevertheless feel free to contact us info@itcl.es for further information as we are continually evolving the core and the tools.
We can of course also implement what do you need (Algorithms, casuistic, 3D objects and environment) ad-hoc
SIGEDA For Body Posture Estimation
The implementation for Body Posture Estimation has mainly 5 configuration modules to allow a versatile generation of data:Characters and joints:
- Selection of the different avatars that will be included in the images.
- Selection of the base posture: standing or seated.
- Selection of involved joints
- For each joint, the limits of movement can be configured (per each angle joint)
- The number of interpolations of each involved joint/movement limit can be configured.

Environments and locations:
Currently, there are 2 virtual environments implemented, an office and a factory. And several predefined positions for the avatars that can be included or not.

Cameras type and selection:
There are several cameras around each position that can be activated or deactivated to generate images for different angles. Also, the camera parameters can be fixed in order to mimic different camera models.

Resolution:
The final screen allows the user to select the resolution of the images and provides feedback about the number of images that will be generated and estimated size on disk.
- Synthetic image generated.
- Synthetic image with the segmentation information.
- CSV file with the 2D position of each joint in the image, info about the visibility of the joint and 3D position of each joint respect to the camera



Images of the Office
Images of the Factory
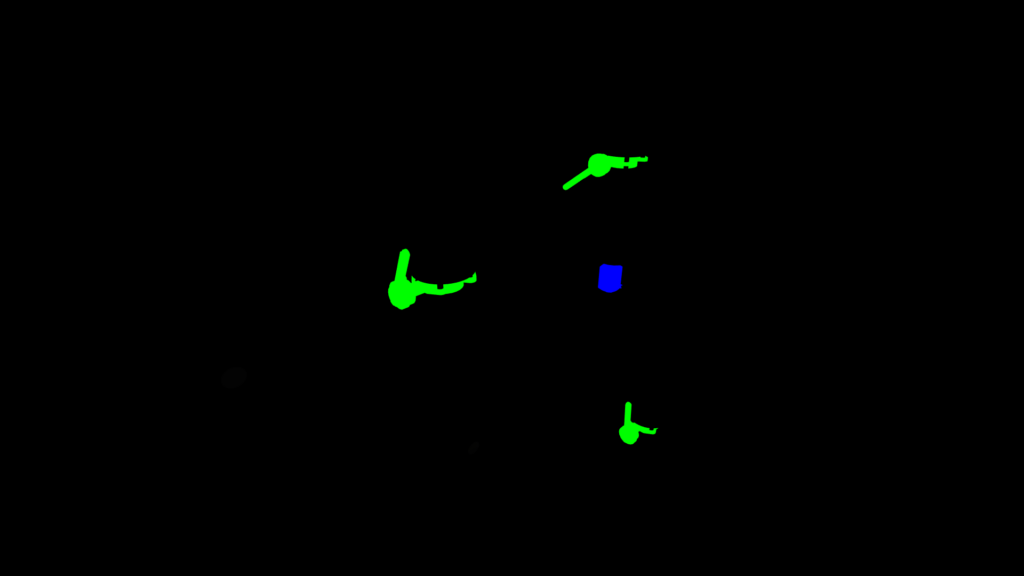
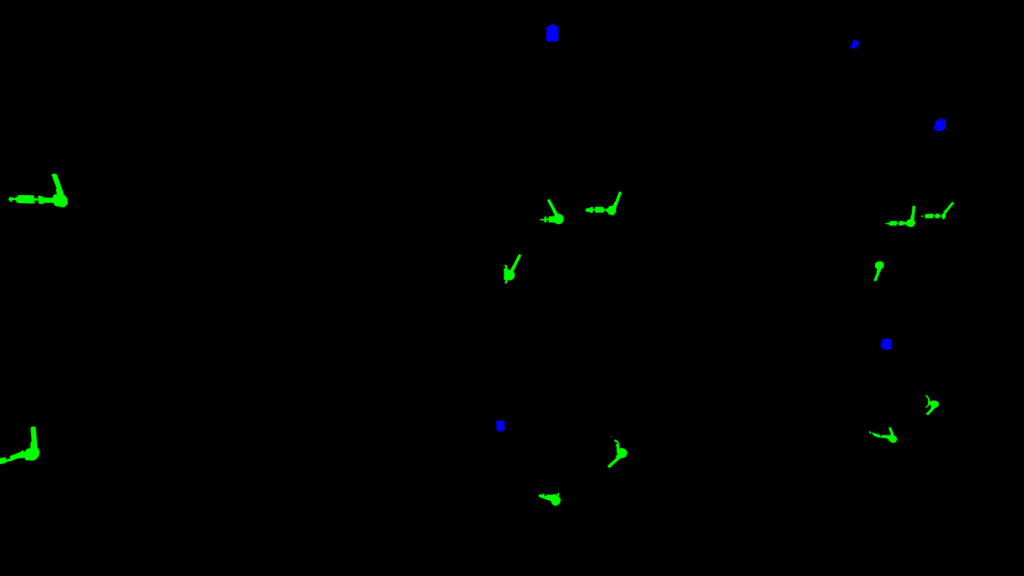
SIGEDA For Objects recognition and status analysis
This second implementation takes a slightly different approach due to the problem that we want to solve. We need to detect valves and indicators in an industrial environment. We also want to get the state of the valves: open, close or semi-open. In this implementation, we also focused on the realism and quality of the 3D environment and images. The user can load two different environments and control a free camera to move thought the Virtual Reality environment and take images on demand. Each time the user takes a picture the system save a High-Quality Image, the segmented image and labels about each valve and indicator visible into the image.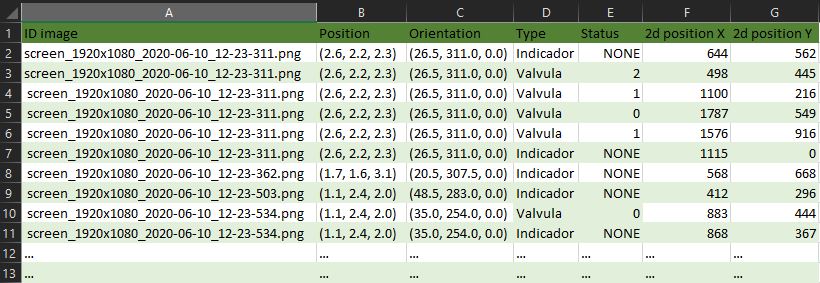

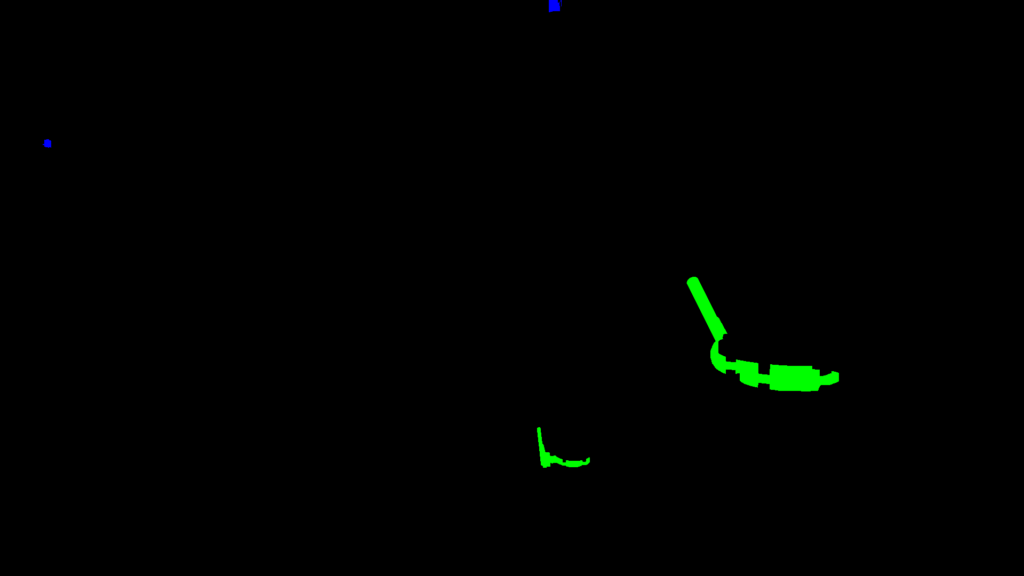
Images of the environment