Simulación y Realidad Virtual
«La productividad nunca es un accidente. Siempre es el resultado de un compromiso con la excelencia, planificación inteligente y esfuerzo concentrado» (Paul J. Meyer)
SIGEDA: Generador de Imágenes Sintéticas para el aumento de datos de entornos de RV para proyectos de Aprendizaje Profundo y Visión por Computadora
La familia de productos relacionados se denomina SIGEDA «Generador de Imágenes Sintéticas para el Aumento de Datos» cuyo núcleo puede ser utilizado o personalizado para abordar diferentes problemas. El ITCL ha realizado algunas implementaciones específicas (que se muestran a continuación) para generar datos etiquetados para la Estimación de la Postura Ergonómica y la Localización y Clasificación de Objetos. El núcleo del sistema actual nos permite crear fácilmente nuevas soluciones personalizadas.
A continuación, una visión general de lo que actualmente está integrado en el núcleo:
- Múltiples fondos disponibles mediante la selección de varios entornos 3D.
- Selección de varias posiciones y ángulos de cámara predefinidos.
- Posibilidad de añadir una cámara totalmente controlable para navegar dentro del entorno obteniendo ángulos o posiciones específicas si es necesario.
- Parámetros de la cámara configurables como: FOV, resolución, parámetros intrínsecos (distancia focal, etc.), y aberraciones ópticas.
- Detección de oclusiones entre elementos.
- Etiquetas relacionadas con los elementos de interés: Posición 3D, posición 2D en la imagen y Regiones de interés.
- Generación de imágenes para problemas de segmentación densa.
- Otras herramientas específicas de comportamiento necesarias para el problema específico (por ejemplo Animación del Avatar 3D, estados aleatorios en objetos 3D, animaciones, secuencias, multicámara por cuadro…)
Quieres más información
Objetivos
- El objetivo principal es tener una forma eficiente de generar una gran cantidad de datos sintéticos. Nuestra solución actual puede generar alrededor de 400-1.000 imágenes etiquetadas por minuto en un PC comercial (i7 + Nvidia Geforce 2060RTX) dependiendo de la resolución y la aplicación. La solución puede ser fácilmente escalada.
- Generación de suficiente variabilidad en las imágenes, entorno, punto de vista, avatares… que eviten el sobreajuste durante la etapa de entrenamiento de las redes neuronales.
- Gran versatilidad en la información etiquetada. Al estar en un entorno virtual todos los elementos son perfectamente conocidos y pueden ser usados como una verdad de la Tierra. Es posible obtener cualquier información relacionada con la posición, estado, orientación, color, características… de cualquier objeto del entorno
Por supuesto, también podemos implementar lo que necesite (Algoritmos, casuística, objetos 3D y entorno) ad-hoc.
SIGEDA para la estimación de la postura corporal
La implementación de la Estimación de la Postura Corporal tiene principalmente 5 módulos de configuración para permitir una generación versátil de datos:
Personajes y articulaciones:
- Selección de los diferentes avatares que se incluirán en las imágenes.
- Selección de la postura base: de pie o sentado.
- Selección de las articulaciones involucradas:
- Para cada articulación, los límites de movimiento pueden ser configurados (por cada articulación de ángulo)
- Se puede configurar el número de interpolaciones de cada límite conjunto/movimiento involucrado.

Entornos y lugares:
Actualmente, hay 2 entornos virtuales implementados, una oficina y una fábrica.
En cada uno existen varias posiciones predefinidas para los avatares que pueden ser incluidas o no.


Tipo y selección de cámaras:
Hay varias cámaras alrededor de cada posición que pueden ser activadas o desactivadas para generar imágenes para diferentes ángulos.
También se pueden fijar los parámetros de la cámara para imitar diferentes modelos de cámara.


Resolución:
La pantalla final permite al usuario seleccionar la resolución de las imágenes y proporciona información sobre el número de imágenes que se generarán y el tamaño estimado en el disco.

En esta implementación específica de SIGEDA la salida del sistema consiste en:
- Imagen sintética generada.
- Imagen sintética con la información de segmentación.
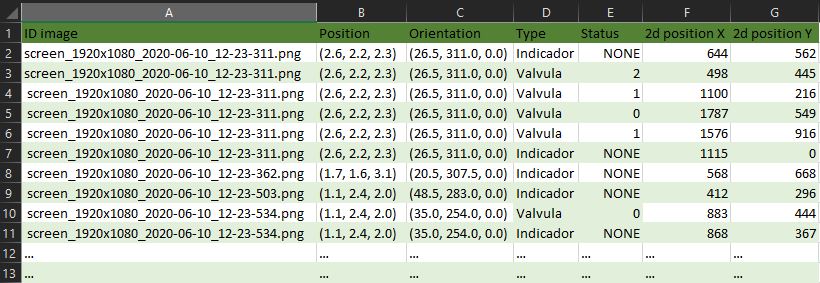
- Archivo CSV con la posición 2D de cada articulación en la imagen, información sobre la visibilidad de la articulación y la posición 3D de cada articulación respecto a la cámara.



Galería de ejemplos de Oficina
Galería de ejemplos de Industria
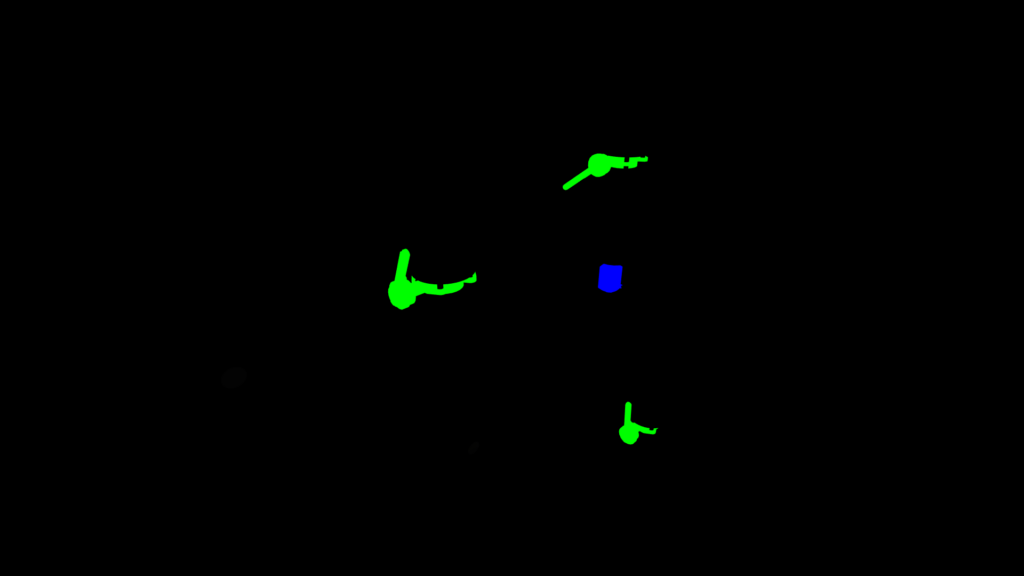
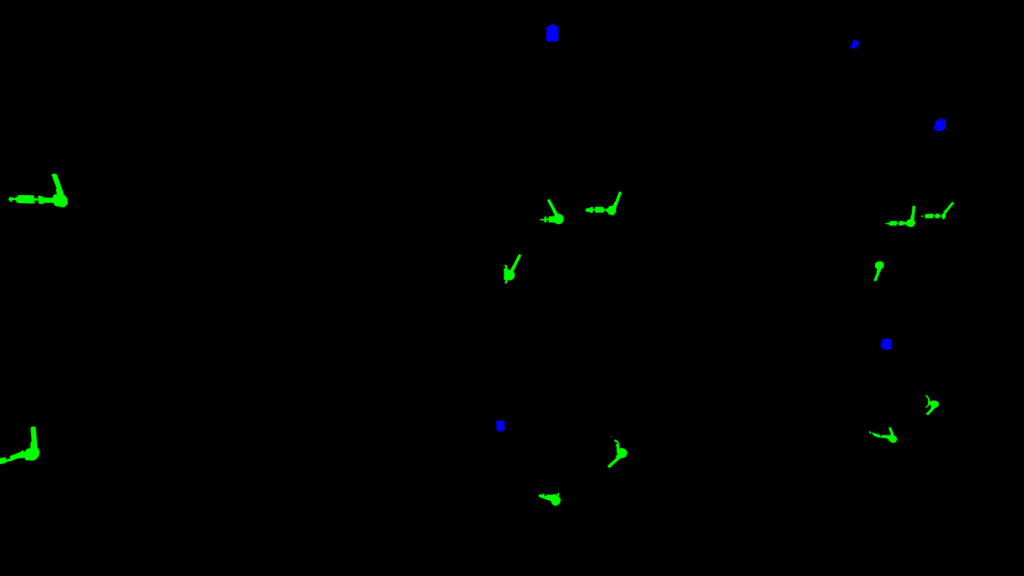
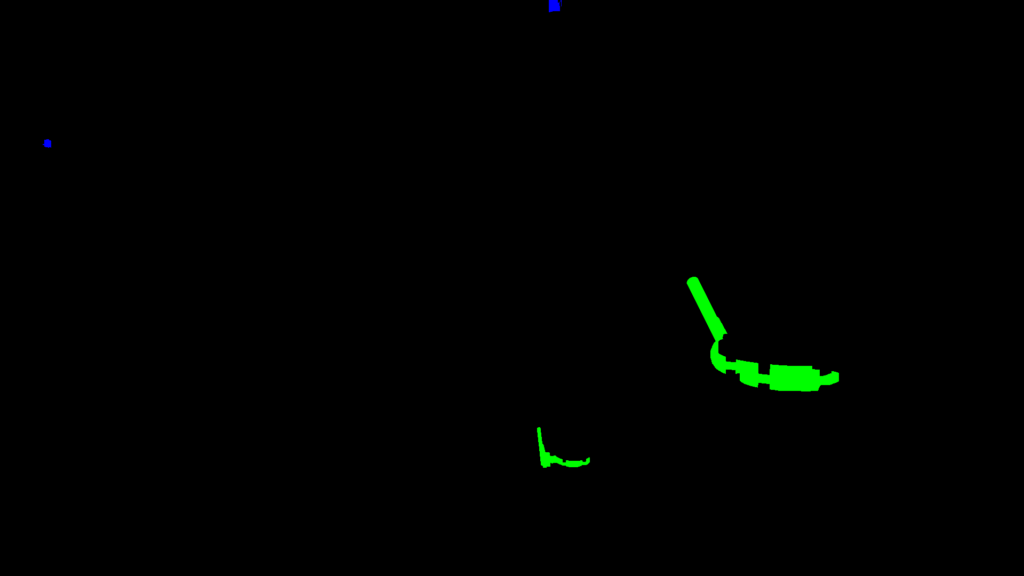
SIGEDA para el reconocimiento de objetos y el análisis de su estado
Esta segunda implementación tiene un enfoque ligeramente diferente debido al problema que queremos resolver. Necesitamos detectar válvulas e indicadores en un entorno industrial. También queremos conocer el estado de las válvulas: abiertas, cerradas o semiabiertas. En esta implementación, también nos centramos en el realismo y la calidad del entorno e imágenes 3D.
El usuario puede cargar dos entornos diferentes y controlar una cámara libre para moverse por el entorno de la Realidad Virtual y tomar imágenes a pedido. Cada vez que el usuario toma una foto el sistema guarda una imagen de alta calidad, la imagen segmentada y las etiquetas sobre cada válvula e indicador visible en la imagen.

Galería de ejemplos